- 原文地址:Modern Face Recognition with Deep Learning
- 原文作者: Adam Geitgey
- 本文永久链接:深度学习中的现代人脸识别(翻译)
- 译者:Vgbhfive
我们学习现代人脸识别的工作原理如果仅仅是用来认识你的朋友那么就太简单了吧。现在我们可以将这项技术推向极限,已解决更重要的问题-威尔·法雷尔 (著名演员) 和 查德·史密斯 (著名摇滚音乐家)。

这些人之一是威尔·法雷尔(Will Farrell)。另一个是查德·史密斯(Chad Smith)。我发誓他们是不同的人!
如何在非常复杂的问题上使用机器学习
到目前为止,在第 1 、2 和 3 中,我们使用机器学习来解决只有一步的孤立问题。所有这些问题都可以通过选择一种机器学习算法,输入数据并获得结果来解决。
但是人脸识别实际上是一系列相关的问题:
- 首先,查看图片并找到其中的所有面孔。
- 其次,专注于每一张面孔,并且能够理解(即使面孔朝向不同的反向或光线不足的地方转动)它们仍然是同一个人。
- 第三,能够挑选出与其他面孔区分开来的脸部特征,例如眼睛大小,脸部长度等。
- 最后,将该面孔的独特特征与已有认识的人中进行比对,以确定该人的名字。
作为人类,人类的大脑可以自动且立即执行上述的操作。然后实际上,人类很擅长识别在日常生活中见到的所有面孔。
然而计算机并不具备这种能力(至少现在还不太行),因此我们必须教会计算机如何分别完成这些过程的每一个步骤。
我们需要建立一个管道,在其中分别解决人脸识别的每一个步骤,并将当前步骤的结果传递到下一步。换句话说,就是我们需要将把几种机器学习算法链接到一起。

用于检测人脸的基本管道可能如何工作
人脸识别
在解决这个问题中,对于每一步,我们将学习不同的机器学习算法。我不会完全解释每种算法,但是你可以学习到每种算法的主要思想,并且可以学习如何 Python 中构建自己的人脸识别系统。
1、找出所有的面孔
开发流程中的第一步就是人脸检测。显然,我们只有先找出图片中的所有面孔,然后才能将他们全部分开。
如果你在过去的十年里使用过任何智能手机上的相机,则可能已经看到了人脸检测的实际效果:
人脸检测是相机的一项重要功能。当相机可以自动挑选出面孔时,可以确保在拍摄照片之前将所有面孔都对准焦点。但是,我们要将这一功能用于其他目的-查找要传递到下一步的图像区域。
在 2000 年代初期,Paul Viola 和 Michael Jones 发明了一种面部检测方法,该方法能够以足够快的速度运行在廉价相机上,从而成为人脸检测的主流。
但是,现在有了更加可靠的解决方案。我们将使用一种在 2005 年发明的方法,称为“**定向梯度直方图**” ,简称 HOG 。
要想在图像中查找面孔,我们需要将图像设置为黑白,因此我们不需要颜色数据来查找面孔:
然后,我们将会一次查看图像中的每一个像素。对于每一个像素,我们要查看直接围绕他的像素:
我们的目标是弄清楚当前元素与直接围绕他的像素相比有多暗。然后,我们绘制一个箭头表示图像朝哪个方向变暗:
仅看一个像素和触摸它的像素,图像朝右上方变暗。
如果对图像中的每个像素重复该过程,则最终每个像素都会被箭头替代。这些箭头称之为渐变,它们显示了整个图像从明到暗的流动: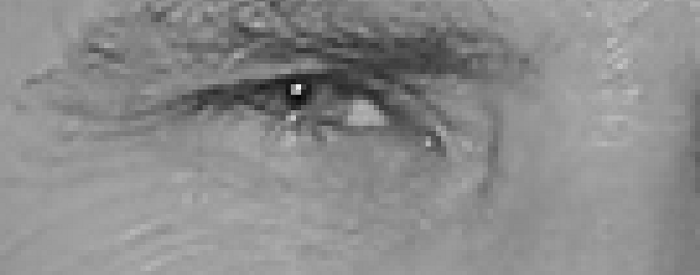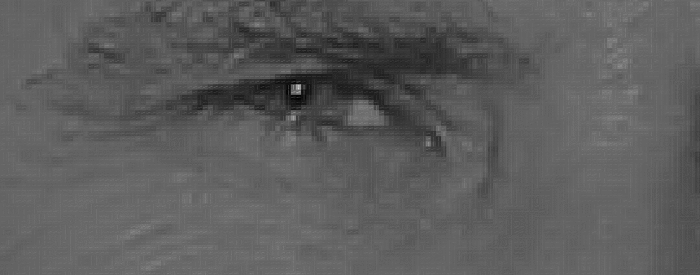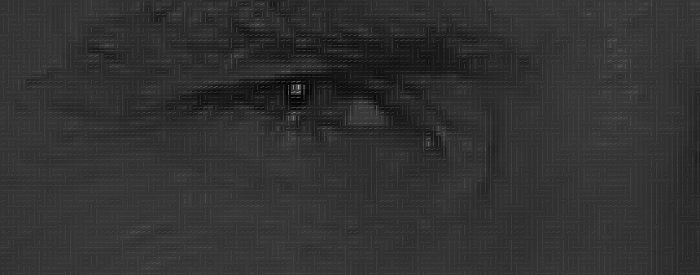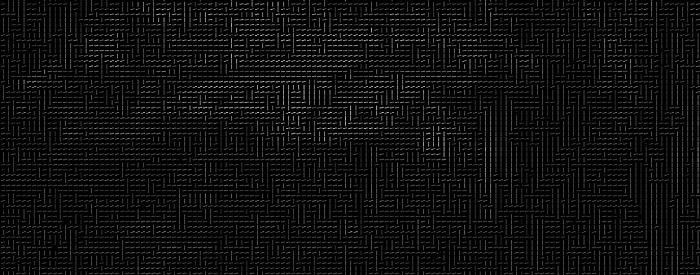
这似乎是一件随机的事情,但是确实有充分的理由将像素转换为渐变。如果我们直接分析像素,同一张照片的真正黑暗的图像和真正明亮的图像将具有完全不同的像素值。但是,仅考虑相邻像素之间的亮度变化的反向,则黑暗的图像和明亮的图像都将具有相同的特定表示。这样会使得问题更加容易解决。
如果如上述的话,为每一个元素保存渐变会给我们带来太多的细节。此时,如果我们能够以更高的层次看到明暗的基本流程那就更棒了,这样我们就可以看到图像的基本图案。
为此,我们将图像分成每个 16x16 像素的小方块。在每一个小方块中,我们将计算出每个主要方向上有多少个渐变点(向上、垂直、向右等)。然后,我们先图像中的那个正方形替代为最强的箭头反向。
最终结果就变成了,我们将原始图像转换为非常简单的表示形式,以一种简单的方式捕获面部的基本结构:
原始图像被转换为HOG表示,可以捕获图像的主要特征,而与图像的亮度无关。
在此之上,我们已经有了很大的进步。但是要在此 HOG 图像中找到脸部,我们要做的就是找到图像中看起来与其他训练脸部中提取的已知 HOG 模式最相似的部分。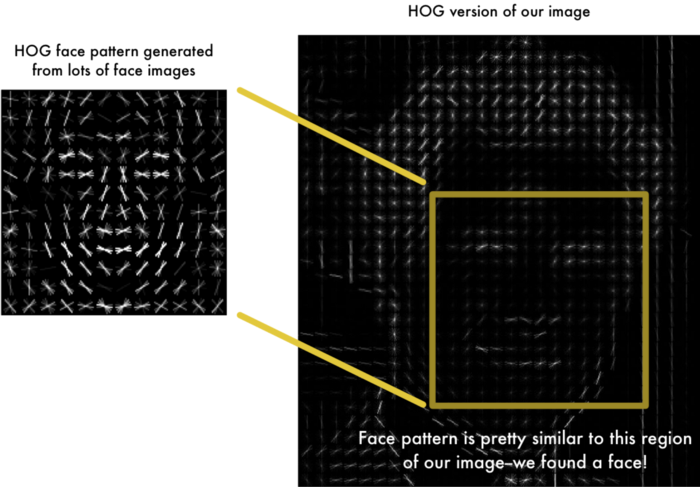
使用此技术,我们就可以轻松地在任何图像中找到人脸。
如果你想自己尝试使用 Python 和 dlib 进行操作,那么下面的 代码 会帮助你如何生成和查看图像的 HOG 表示。
2、摆姿势和投影面
这时,我们会发现一个问题,我们识别出了我们图像中的面孔,当面对不同反向的面孔表情与计算机看起来是完全不一样的:
人们可以轻松地识别出这两个图像都是威尔·法瑞尔的,但计算机会将这些图像视为两个完全不同的人。
为了解决这个问题,我们将尝试使每张图片变形,以使眼睛和嘴唇始终处于图像的样本位置。这个步骤将会在我们接下来的步骤中比较人脸将会变得更加容易。
基于此,我们将使用一种成为人脸界标估计的算法。有很多种方法都可以做到这一点,但是我们将使用 Vahid Kazemi 和 Josephine Sullivan 在 2014 年发明的方法。
基本思想就是,我们得出存在于每个面孔上的 68 个特定的点(称之为地标),即下巴顶部、每只眼睛的外边缘、每根眉毛的内边缘等。然后,我们会训练一种机器学习算法,能够在任何面孔上找到以下 68 个特定点:
在每张面孔上找到68个地标。
这是在测试图像上找到的 68 个面部地标的结果:
现在我们知道了眼睛和嘴巴的存在,我们进行简单的旋转、缩放和剪切图像,以使眼睛和嘴巴尽可能的居中。在这之中,我们不会做任何的 3d 变形,我们只使用保留平行线的基本图像变换(例如旋转、缩放),如此称之为仿射变换。
现在无论面孔如何进行旋转,我们都可以使眼睛和嘴巴居中于图像中大致相同的位置,这样就能使我们的下一个步骤更加准确。
如果你想自己尝试使用 Python 和 dlib 进行操作,这里查找人脸界标的 代码 能很好地帮助到你。
3、对面孔进行编码
到了这一步我们已经解决了大部分的问题,那么接下来就是如何将图像中的面孔进行识别并标记。
为此我们需要一种从每张面孔中提取一些基本测量值的方法。然后,我们可以用相同的方式测量未知面孔,并用最接近的测量值找到已知面孔(例如我们可以测量妹子耳朵的大小、两眼之间的距离、鼻子的长度等)。
测量面孔的最可靠方法
事实证明,对于我们人类来说显而易见的测量值(例如眼睛颜色)对于计算机查看图像中的各个像素而言并没有任何意义。研究人员发现,最准确的方法应该是让计算机找出测量值以自行收集。在确定面孔的哪些部位很重要时,深度学习比人类做得更好。
解决方案就是训练一个深度卷积神经网络。但是,于其训练他来识别图片对象,我们不如训练它来为每个面孔生成 128 个测量值。
训练过程通过一次查看 3 张图像来进行:
- 加载已知人物的训练脸部图像。
- 加载同一个已知人物的另一张图像。
- 加载完全不同的人的图像。
然后,该算法查看针对这三个图像中的每个图象当前正在生成的测量结果。接着,他会稍微调整神经网络,以确保他为 #1 和 #2 生成的测量值稍微接近一点,同时确保 #2 和 #3 的测量值稍微分开一点:
在对成千上万的人类的数百万张图像重复比对此过程百万次之后,神经网络学会了可靠地为每个人生成 128 个测量值。同一个人的任何十张不同图片都应进行大致相同的测量。
人类将机器学习为每个面孔生成的 128 个测量值称为嵌入。将复杂的原始数据(例如图片)简化为计算机生成的数字列表的想法在机器学习中产生了很多。
编码我们的面孔图像
训练卷积神经网络以输出人脸嵌入的过程需要大量数据和计算功能。目前即便是使用 NVidia Telsa 显卡,也需要大约 24 小时左右的的连续训练才能获得良好的准确性。
不过,一旦对神经网络进行了训练,我们就可以生成任何脸部的测量结果,甚至是以前从未见过的测量结果。因此,在这里你可以找到已经训练好的神经网络。
到这一步,我们需要做的就是通过已经预先训练的神经网络运行人脸图像,以获取每个面孔的 128 个测量值。这时测试图像的尺寸:
那么,对于这 128 个准确的测量值到底是测量了面孔的哪一部分呢?事实证明,我们并不知道,但是这对我们来说并不重要。我们需要关心的是,当查看同一个面孔时的两张图像时,神经网络会生成几乎相同的测量值。
如果你也想自己尝试这个步骤,OpenFace 提供了对应的 lua 脚本,该脚本将在文件夹中生成所有图像的嵌入并将它们写入 csv 文件中。
从编码中查找面孔的姓名
最后一步实际上是整个过程中最简单的步骤,我们需要做的就是在已知数据库中找到最接近我们测试图像的面孔的姓名。
为此我们可以使用任何基本的机器学习分类算法来做到这一点。不需要花哨的深度学习技巧,我们仅使用一个简单的线性 SVM 分类器,至于其他的许多分类算法都是可以使用的。
我们需要做的就是训练一个分类器,该分类器可以从新测试图像中获取测量值,并告诉哪个已知人物最接近匹配项。运行此分类器需要尽可能的快,而分类器的结果就是该人的名字。
至此,我们开始了测试。首先,我训练了一个分类器,其中嵌入了 Will Ferrell、Chad Smith 和 Jimmy Falon 的大约 20 张图像:
然后就是对应的测试效果了。
效果很明显就出来了,神经网络对于不同姿势的面孔(甚至是侧面)都是可以完美识别。
回顾
我们回顾以下上面的步骤:
- 使用 HOG 算法对图片进行编码,以创建图片的简化版本。使用此简化的图像,找到图像中最看起来像人脸的普通 HOG 编码的部分。
- 通过找到面部的主要地标来找出面部的姿势。一旦找到这些地标,就可以使用它们使图像变形,以使眼睛和嘴巴居中。
- 通过神经网络传递居中的脸部图像,该网络知道如何测量脸部特征。同时保存这 128 个测量值。
- 查看我们以前测量过的所有面孔,看看哪个人的测量值与现在需要识别的面孔测量值最接近。那就是我们最终的结果。
上面步骤中使用的 OpenFace 已经由作者发布了一个新的基于 Python 的人脸识别库 - face_recognition。
引用
https://github.com/ageitgey/face_recognition#face-recognition
https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
https://github.com/cmusatyalab/openface
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!