基础
图数据库是基于图论实现的一种新型 NoSQL 数据库。他的数据存储结构和数据的查询方式都是以图论为基础的。图论中图的基本元素为节点和边,在图数据库中对应的就是节点和关系。
图数据模型
图数据库要存储具体的图数据,最终落实为具体的数据文件,自然就涉及特定的图数据模型。
常用的有三种:
- 属性图。
- 超图。
- 三元组。
符合以下特征的图数据模型就成为属性图:
- 包含节点和关系。
- 节点可以有属性(键值对)。
- 节点可以有一个或多个标签。
- 关系有名字和方向,并总是有一个开始节点和一个结束节点。
- 关系也可以有属性。
超图适用于多对多关系。例如,常见的有房产拥有关系。
三元组是一个包含主谓宾的数据结构。例如,张三和李四拥有一百块钱等。
图计算引擎
图计算引擎是能够组织存储大型图数据集并且实现了全局图计算算法的一种数据库核心构件。
图计算引擎的工作流程,它包含一个具有联机事务处理过程的数据库记录系统,图计算引擎用于响应终端或应用进程运行时发来的查询请求,周期性从记录系统中进行数据抽取、转换和加载,然后将数据从记录数据系统读入到图计算引擎并进行离线查询和分析,最后将查询、分析的结果返回给用户终端或应用程序。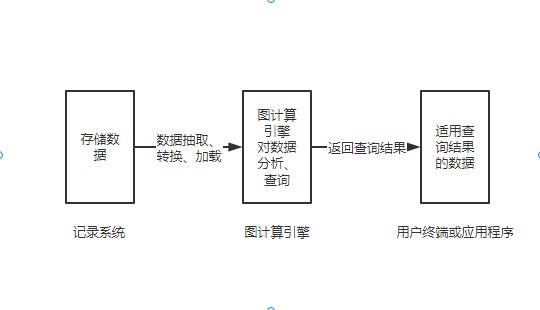
较为流行的图计算引擎有两种:
- 单机图计算引擎。
Cassovary。 - 分布式图计算引擎。
Pegasus和Giraph。
概述
Neo4j 实现了专业数据库级别的图数据模型的存储。
与普通的图处理或内存级数据库不同,Neo4j 提供了完整的数据库特性,包括以下内容:
- 支持
ACID事务。Neo4j通过ACID事务提供真正的数据安全,通过事务来保证数据在硬件故障或者系统崩溃得到情况下数据不丢失。 - 集群支持。
Neo4j使用多副本主从复制的方式构建高可靠性集群,支持大数据集合并且可以不断扩展其容量,可存储数百万亿个实体。 - 备份与故障转移。
- 本地化的数据库。
Neo4j自底向上构成一个图数据库。它的体系结构旨在优化快速管理、存储和遍历节点和关系。 - 界面友好。
Neo4j提供了一个查询与展示一体化的Web操作界面。 - 声明式图查询语言。
Cypher是一种声明式图数据库查询语言,它表现力丰富,查询效率高,其地位与其他关系型数据库中的SQL语言类似。 - 代码开源。
结构
Neo4j 最初的设计动机在于为了更好的描述实体之间的联系。但传统的关系型数据库更加注重刻画实体内部的属性,实体与实体之间的关系主要是通过外键来实现的,因此在查询一个实体的关系时需要 join 操作,特别是深层次的关系查询时需要大量的 join 操作,而 join 操作通常又非常耗时。
免索引邻接
Neo4j 为了保证关系查询的速度,即免索引邻接属性,数据库中的每个节点都会维护与他相邻节点的引用。因此每个节点都相当于与它相邻节点的微索引,这比使用全局索引的代价要小很多。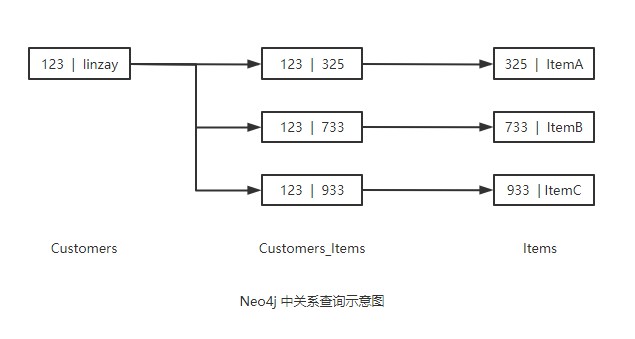
使用免索引邻机制,每个节点都有直接或者间接指向其相邻节点的指针。
免索引邻接针对 RDBMS 中的关系查询的缺点做了改进:
- 免索引邻接使用遍历物理关系的方法查找,比起全局索引来说代价要小得多。
- 当索引建立后试图反向遍历时,建立的索引就不起作用了。
底层索引结构
从宏观角度来说,Neo4j 中仅仅包含两种数据类型和一种存储类型:
- 节点(
Node): 节点类似于E-R图中的实体(Entity)。每一个实体可以有零个或多个属性(Property),这些属性以key-value对的形式存在。属性没有特殊的类别要求,同时每个节点还具有响应的标签(Label),用来区分不同类型的节点。 - 关系(
Relationship): 关系也类似于E-R图中的关系(Relationship)。一个关系有起始节点和终止节点。另外,与节点一样,关系也能够有自己的属性和标签。 - 属性(
Property)。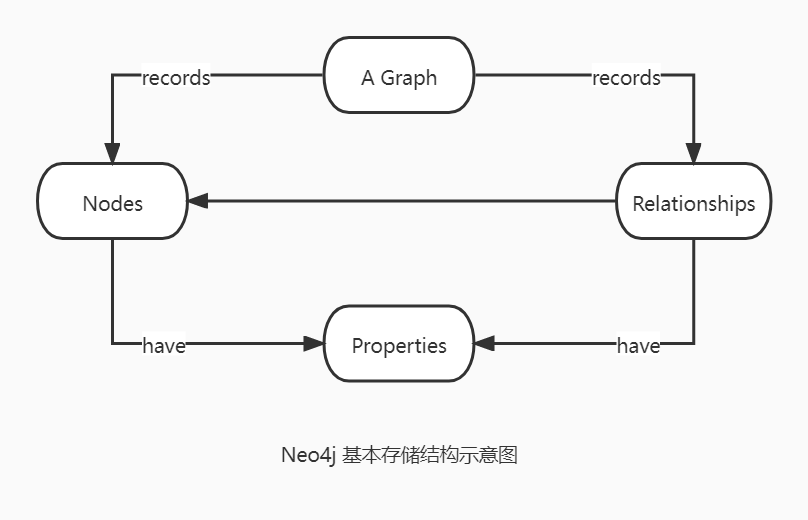
节点和关系分别采用固定长度存储。其中节点为 9 字节,关系为 33 字节。
节点存储文件用来存储节点的记录,文件名为 neostore.nodestore.db 。节点记录的长度为固定大小,如图中所示,每个节点记录的长度为 9 个字节。格式为: Node:inUse + nextRelId + nextPropId 。
inUse:1表示该节点被正常使用,0表示该节点被删除。nextRelId: 该节点的下一个关系ID。nextPropId: 该节点的下一个属性ID。
Node[12,used=true,rel=11,prop=22] 采用固定字节长度的记录可以快速地查询到存储文件中的节点。
关系存储文件用来存储关系的记录,文件名为 neostore.relationshipstore.db 。像节点的存储一样,关系存储区的记录大小也是固定的。格式为: Relationship:inUse + firstNode + secondNode + relType + firstPrevRelId + firstNextRelId + secondPrevRelId + secondNextRelId + nextPropId 。
inUse:1表示该节点被正常使用,0表示该节点被删除。firstNode: 当前关系的起始节点。secondNode: 当前关系的终止节点。relType: 关系的类型。firstPrevRelId & firstNextRelId: 起始节点的前一个和后一个关系的ID。secondPrevRelId & secondNextRelId: 终止节点的前一个和后一个关系ID。nextPropId: 该节点的下一个属性ID。
Relationship[11,used=true,source=12,target=11,type=2,sPrev=-1,sNext=-1,tPrev=-1,tNext=10,prop=23] 采用固定字节长度的记录可以快速地查询到存储文件中的关系。
Neo4j 中有一个 .id 文件用来保持对未使用记录的跟踪,用来回收未使用的记录占用的空间。
属性记录的物理存储位置在 neostore.propertystore.db 文件中。与节点和关系的存储记录一样,属性的存储记录也是固定长度。每个属性记录包含四个属性块和属性链中下一个属性的 ID。属性链是单向链表,而关系链是双向链表。
属性索引文件主要用于存储属性的名称,属性索引的值部分存储的是指向动态内存的记录或者内联值,短字符串和短数组会直接内联在属性存储记录中。当长度超过属性记录中的 propBlock 长度限制后,会单独存储在其他的动态存储文件中。
Neo4j 中有两种动态存储: 动态字符串存储(neostore.propertystore.db.strings)和动态数组存储(neostore.propertystore.db.arrys)。动态存储记录是可以扩张的,如果一个属性长到一条动态存储记录仍然无法完全容纳时,可以申请多个动态存储记录逻辑上进行连接。
遍历方式
每个节点记录都包含一个指向该节点的第一个属性的指针和联系链中第一个联系的指针。要读取一个节点的属性,从指向第一个属性的指针开始,遍历整个单向链表结构。要找到一个节点的关系,从指向的第一个关系开始,遍历整个双向链表,直到找到感兴趣的关系。一旦找到了感兴趣关系的记录,就可以与使用和查找节点属性一样的方法查找关系的属性。也可以很方便的获取起始节点和结束节点的 ID。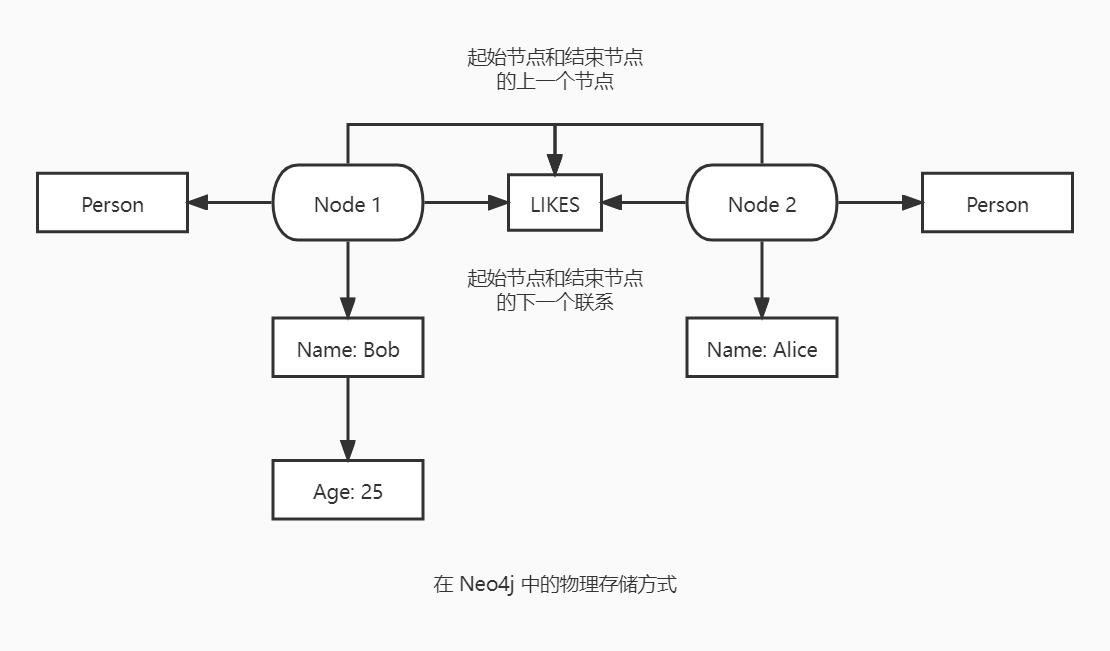
每一个列表都是双向链表,因此我们可以在任何一个方向上进行快速便利和高效地插入和删除。
通过固定大小的存储记录和指针 ID,只要跟随指针就可以简单地实现遍历并且高速执行。要遍历一个节点到另一个节点的特定关系,在 Neo4j 中只需要遍历几个指针,然后执行一些低成本的 ID 计算即可,这相较于全局索引的时间复杂度要低很多,这就是 Neo4j 实现高效遍历的秘密。
- 从一个给定节点定位关系链中第一个关系的位置,可以通过计算他在关系存储的偏移量来获得。跟获得节点存储位置的方法一样,使用关系
ID乘以关系记录的固定大小即可找到关系在存储文件中的正确位置。 - 在关系记录中,搜索第二个字段可以找到第二个节点的
ID。用节点记录大小乘以节点ID可以得到节点在存储中的正确位置。
存储优化
Neo4j 支持存储优化(压缩和内联存储属性值),对于某些短字符的属性可以直接存储在属性文件中(neostore.propertystore.db)。Neo4j 还可以对属性名称的空间严格维护。属性名称都通过属性索引文件从属性存储中间接引用。属性索引允许所有具有相同名称的属性共享单个记录。Neo4j 采用了缓存策略,保证那些经常访问的数据可以快速地被多次重复访问。其中页面置换算法是基于最不经常使用的页置换(LFU, Least Frequently Used)缓存策略,根据页面的常用程度进行微调。
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!