前序 本篇文章其目的在于实践《量化投资》 而特意编写,内容主要包含收集数据 、整理和分析数据 、因子指标计算 、策略制定 、量化回测 。
阅读本篇需要一定的 Python 基础、金融基础知识和计算机编程经验,各位予取予求。
数据收集及整理 本次数据采用的是中国平安近一年的历史股票数据,其数据指标包含开盘价 、最高价 、最低价 、收盘价 、成交量 、成交额 、换手率 。
获取历史数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 from selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsfrom browsermobproxy import Serverimport timeimport jsonimport requestsimport pandas as pdimport randomdef save_basic_data_to_csv (code, daliy_data ): if len (daliy_data) <= 0 : print (code + ' certificate data length is ' + str (len (daliy_data))) return col_data = {} col_num = len (daliy_data[0 ].split(',' )) for i in range (col_num): col_data[i] = [] for data in daliy_data: rows = data.split(',' ) for i in range (len (rows)): col_data[i].append(rows[i]) data = pd.DataFrame(col_data) data.to_csv(str (code)+'.csv' , index=False ) def data (code ): url = url_where(code) server = Server('selenium_install_path/browsermob-proxy-2.1.4/bin/browsermob-proxy' ) server.start() proxy = server.create_proxy() chrome_options = Options() chrome_options.add_argument('--ignore-certificate-errors' ) chrome_options.add_argument('--proxy-server={0}' .format (proxy.proxy)) browser = webdriver.Chrome(options=chrome_options) proxy.new_har(options={'captureContent' : True , 'captureHeaders' : True }) browser.get(url) time.sleep(2 ) new_har = proxy.har for entry in new_har['log' ]['entries' ]: url = entry['request' ]['url' ] if 'qt/stock/kline/get' in url: header_data = entry["request" ]["headers" ] headers = {item['name' ]: item['value' ] for item in header_data} headers.pop('Accept-Encoding' ) print (headers) response = requests.get(url, headers=headers) content = str (response.content) content = content[content.index('{' ): content.index('}' )+2 ] content = content.replace('\\' , '\\\\' ) data = json.loads(content) print (data['data' ]['code' ]) print (len (data['data' ]['klines' ])) save_basic_data_to_csv(data['data' ]['code' ], data['data' ]['klines' ]) proxy.close() browser.close() def url_where (code ): url = '' prefix = code[0 :1 ] nowTime = int (time.time() * 1000 ) preTime = nowTime - random.randint(3 , 10 ) * 1000 if prefix == '6' : url = 'https://push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery35109638153987050799_' + str (nowTime) + '&secid=1.' + code + '&ut=fa5fd1943c7b386f172d6893dbfba10b&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61&klt=101&fqt=1&end=20500101&lmt=1000000&_=' + str (preTime) elif prefix == '0' or prefix == '3' or prefix == '4' or prefix == '8' : url = 'https://push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery35109638153987050799_' + str (nowTime) + '&secid=0.' + code + '&ut=fa5fd1943c7b386f172d6893dbfba10b&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61&klt=101&fqt=1&end=20500101&lmt=1000000&_=' + str (preTime) return url if __name__ == '__main__' : data('000001' )
原始数据格式如下:
整理数据 1 2 3 4 5 6 7 8 9 10 11 import pandas as pdimport datetimedf = pd.read_csv('./000001.csv' ) df = df.loc[:, ['0' , '1' , '2' , '3' , '4' , '5' , '6' , '10' ]] df.columns = ['date' , 'open' , 'close' , 'high' , 'low' , 'volume' , 'volume_amount' , 'turnover_rate' ] df.set_index(pd.to_datetime(df.date), inplace=True ) df.drop('date' , axis=1 , inplace=True ) df = df[datetime.datetime(2023 , 3 , 27 ):] df
数据经过预处理之后的格式如下:
因子计算 本次使用 简单移动平均线 SMA 因子来构建量化策略。
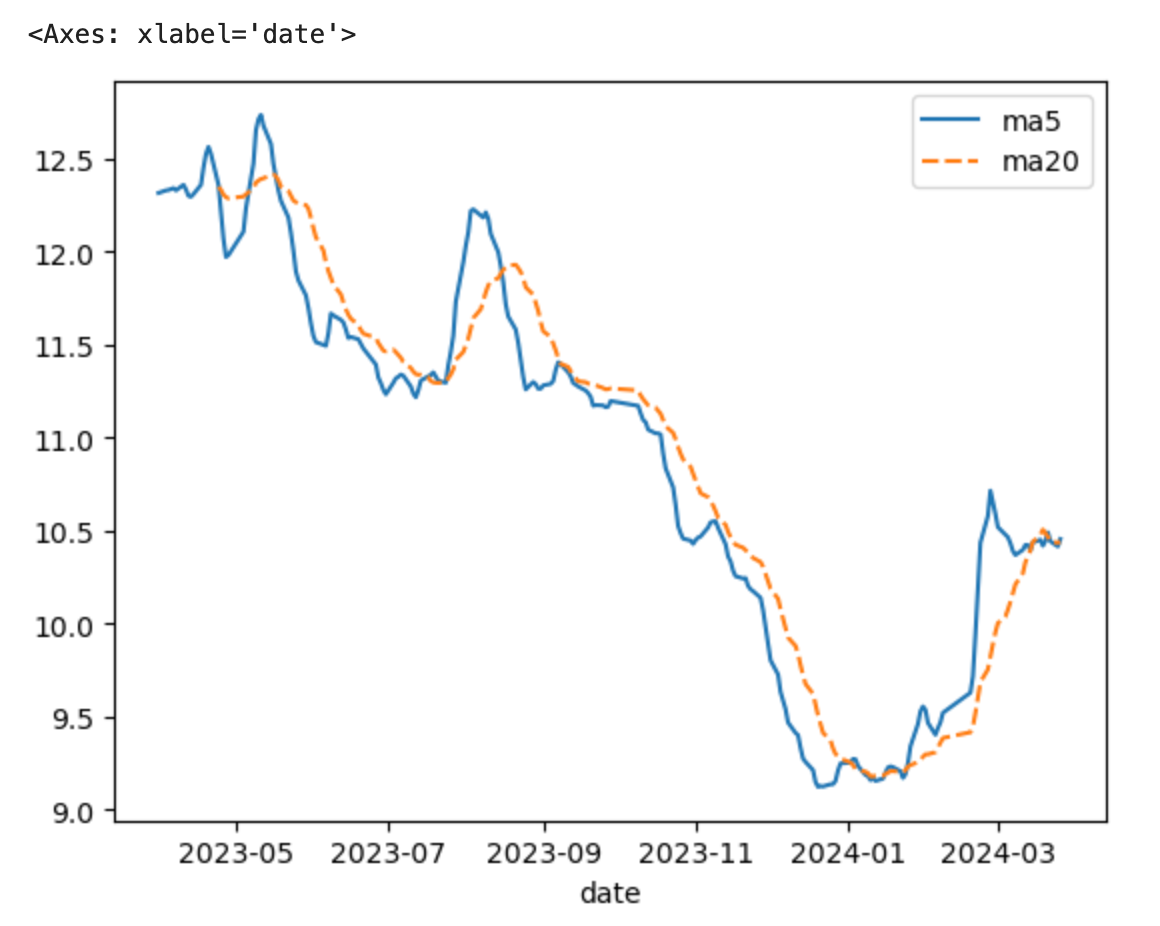
1 2 3 4 5 6 df['ma5' ] = df['close' ].rolling(5 ).mean() df['ma20' ] = df['close' ].rolling(20 ).mean() import seaborn as snssns.lineplot(data=df.loc[:, ['ma5' , 'ma20' ]])
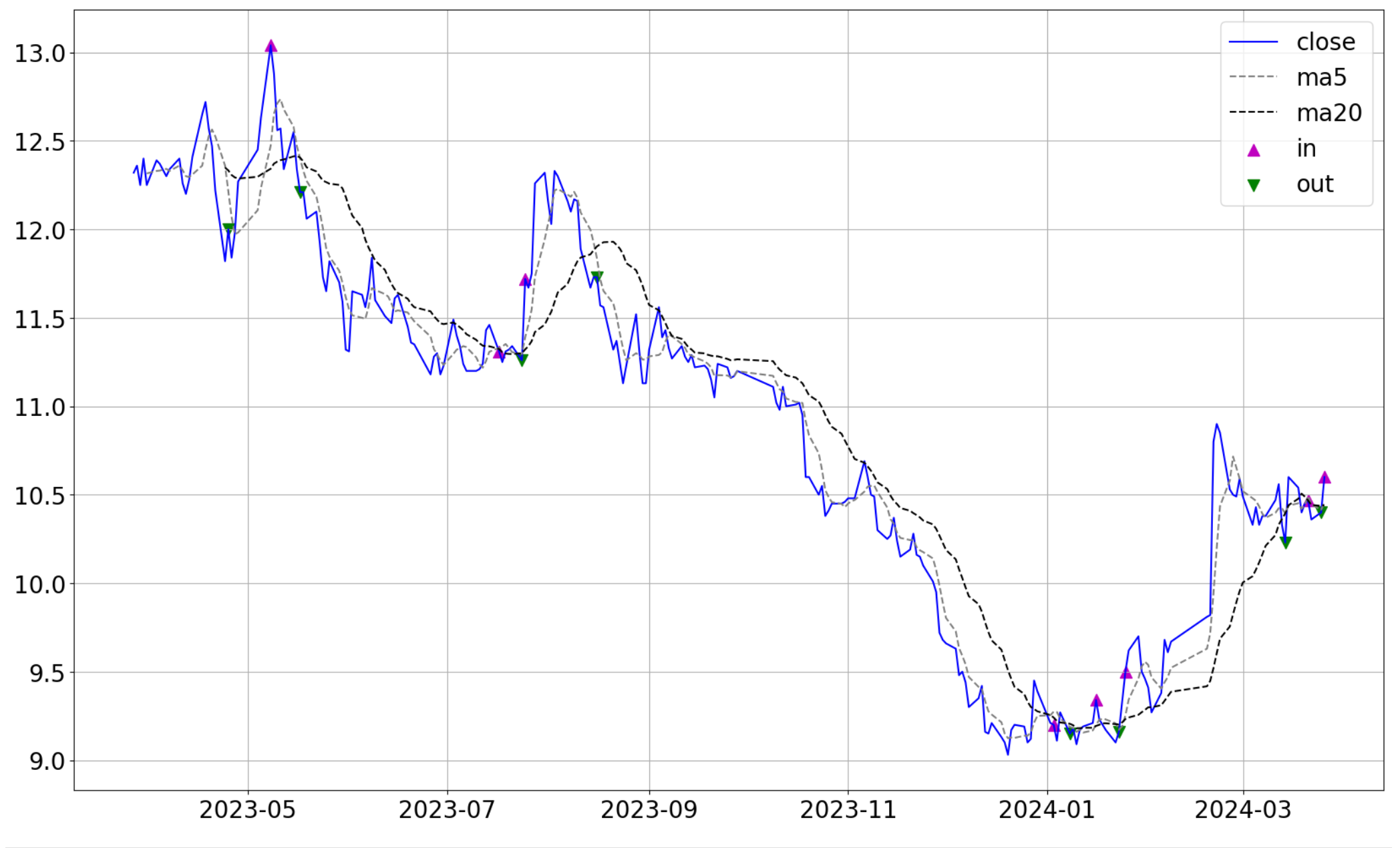
标记行动节点 有了前面计算的 简单移动平均线 SMA 因子数据,之后根据上一篇文章中介绍的均线八大买卖法则来标记买入和卖出的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 df.loc[(df['ma5' ] > df['ma20' ]), 'signal' ] = 1 df.loc[(df['ma5' ] < df['ma20' ]), 'signal' ] = 0 df['order' ] = df['signal' ].diff() import matplotlib.pyplot as pltplt.figure(figsize=(20 ,12 )) plt.plot(df['close' ], color='b' , label='close' ) plt.plot(df['ma5' ], ls='--' , color='gray' , label='ma5' ) plt.plot(df['ma20' ], ls='--' , color='k' , label='ma20' ) plt.scatter(df.loc[df['order' ]==1 ].index, df['close' ][df.order==1 ], marker='^' , s=100 , color='m' , label='in' ) plt.scatter(df.loc[df['order' ]==-1 ].index, df['close' ][df.order==-1 ], marker='v' , s=100 , color='g' , label='out' ) plt.yticks(fontsize=20 ) plt.xticks(fontsize=20 ) plt.legend(fontsize=20 ) plt.grid() plt.show()
量化回测 在得知了有效的量化策略以后,那我们就该在模拟盘中进行回测。
策略模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import backtrader as btcerebro = bt.Cerebro() datafeed = bt.feeds.PandasData(dataname=df, fromdate=datetime.datetime(2023 ,3 ,27 ), todate=datetime.datetime(2024 ,3 ,27 )) cerebro.adddata(datafeed, name='000001.SH' ) print ('读取成功' )cerebro.broker.setcash(1000000.0 ) class ma_qt (bt.Strategy): def __init__ (self ): self.ma_5 = bt.ind.SMA(self.data0.close, period=5 ) self.ma_20 = bt.ind.SMA(self.data0.close, period=20 ) def next (self ): if self.getposition(self.data).size == 0 : if self.ma_5[0 ] > self.ma_20[0 ] and self.ma_5[-1 ] < self.ma_20[-1 ]: self.order = self.buy(self.data, 100 ) print ('买入 100 股成功' ) elif self.getposition(self.data).size > 0 : if self.ma_20[0 ] > self.ma_5[0 ] and self.ma_20[-1 ] < self.ma_5[-1 ]: self.order = self.close(self.data, 100 ) print ('卖出 100 股成功' ) cerebro.broker.set_slippage_perc(perc=0.002 ) cerebro.broker.setcommission(commission=0.001 ) cerebro.addstrategy(ma_qt) cerebro.addanalyzer(bt.analyzers.AnnualReturn, _name='_AnnualReturn' ) cerebro.addanalyzer(bt.analyzers.DrawDown, _name='_DrawDown' ) cerebro.addanalyzer(bt.analyzers.SharpeRatio_A, _name='_SharpeRatio_A' ) cerebro.addanalyzer(bt.analyzers.TimeReturn,_name='_TimeReturn' ) result=cerebro.run()
分析器
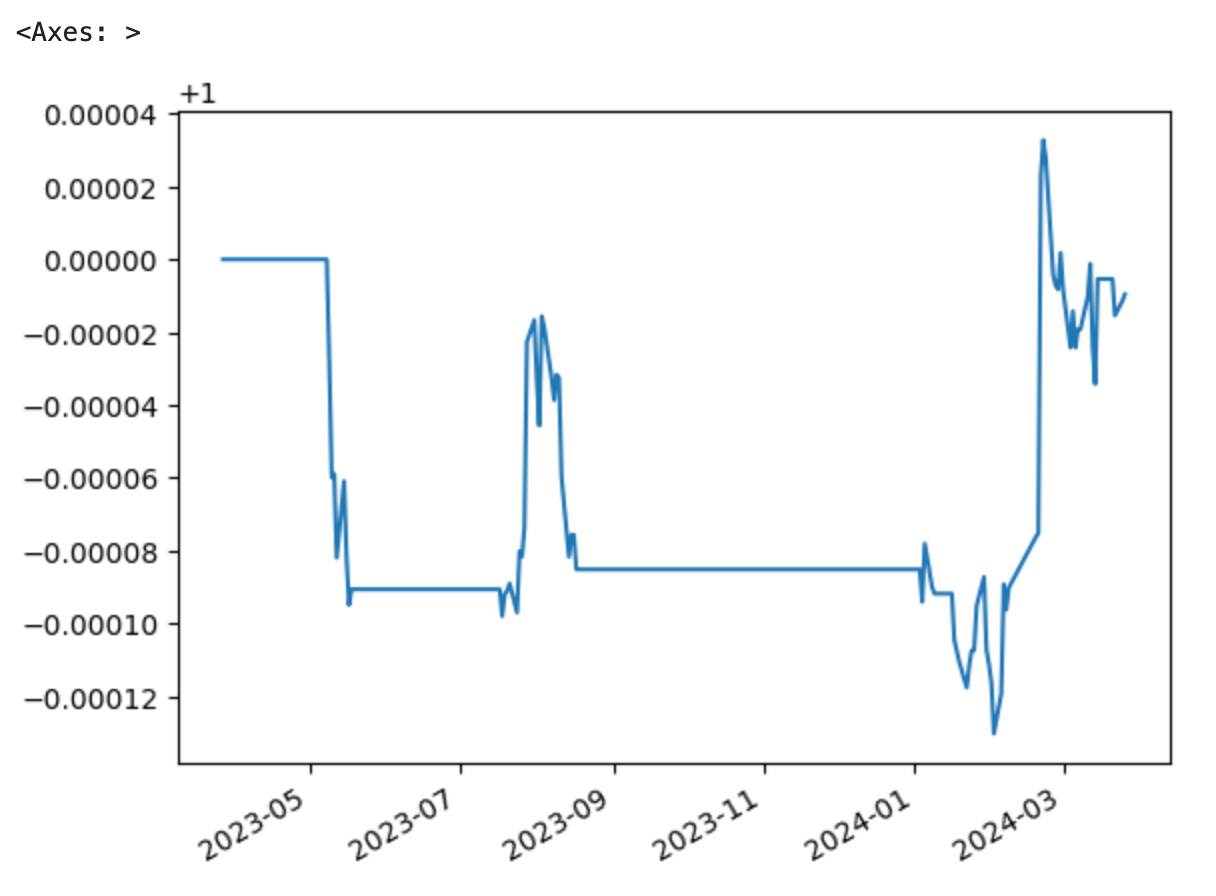
最终收益率1 2 3 ret = pd.Series(result[0 ].analyzers._TimeReturn.get_analysis()) (ret+1 ).cumprod()
最大回撤1 2 result[0 ].analyzers._DrawDown.get_analysis()['max' ]['drawdown' ] * (-1 )
总结
股市有风险,入市需谨慎!
股市有风险,入市需谨慎!
股市有风险,入市需谨慎!
引用 个人备注 此博客内容均为作者学习所做笔记,侵删! 若转作其他用途,请注明来源!